Analyzing HTML Page with Regular Expression
Objectives
Imagine being tasked with a job of creating a spreadsheet, where each row contains basic information about each faculty member at OCADU. With more than 500 individual profiles present on the website, this is certainly a monumental project, and beyond the usual copy-and-paste efforts. As part of this exercise, we wish to achieve the following:
- Programmatically identify all faculty member profile URLs (Graduate Studies only)
- Download and parse relevant information from each page using regular expression
- Present the saved information in CSV format
Survey
A quick look at the filtered faculty list (https://www2.ocadu.ca/all-bios?keys=&field_faculty_value=gradstudies) suggests that each page features a maximum of 48 profile entries, and that this particular list goes up to page 3.
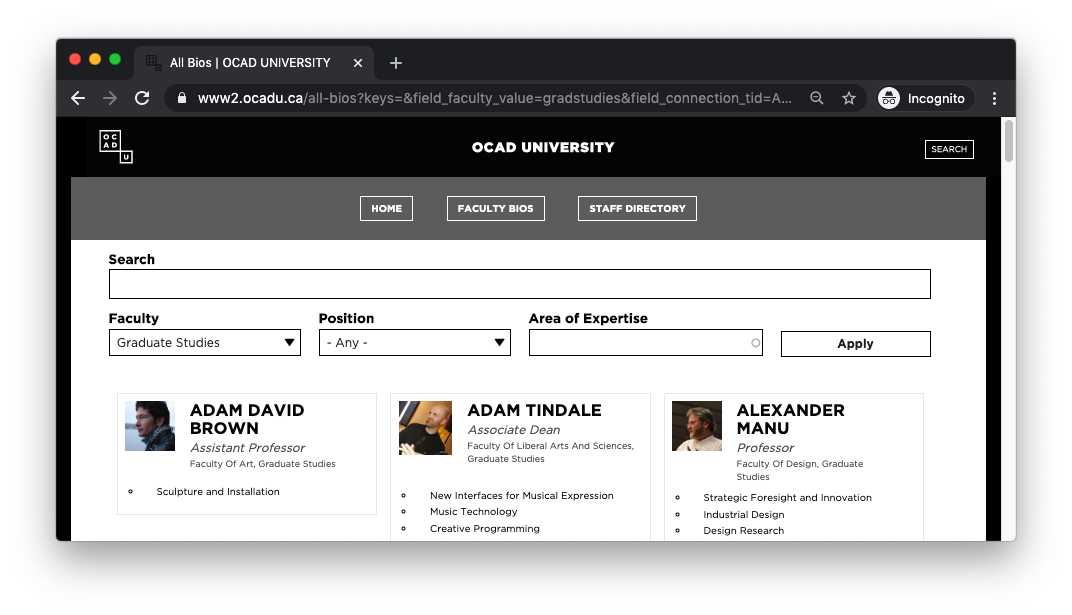
Clicking on a card leads to a profile page (ex. https://www2.ocadu.ca/bio/alexis-morris), which lists a number of essential data points pertaining to the faculty member:
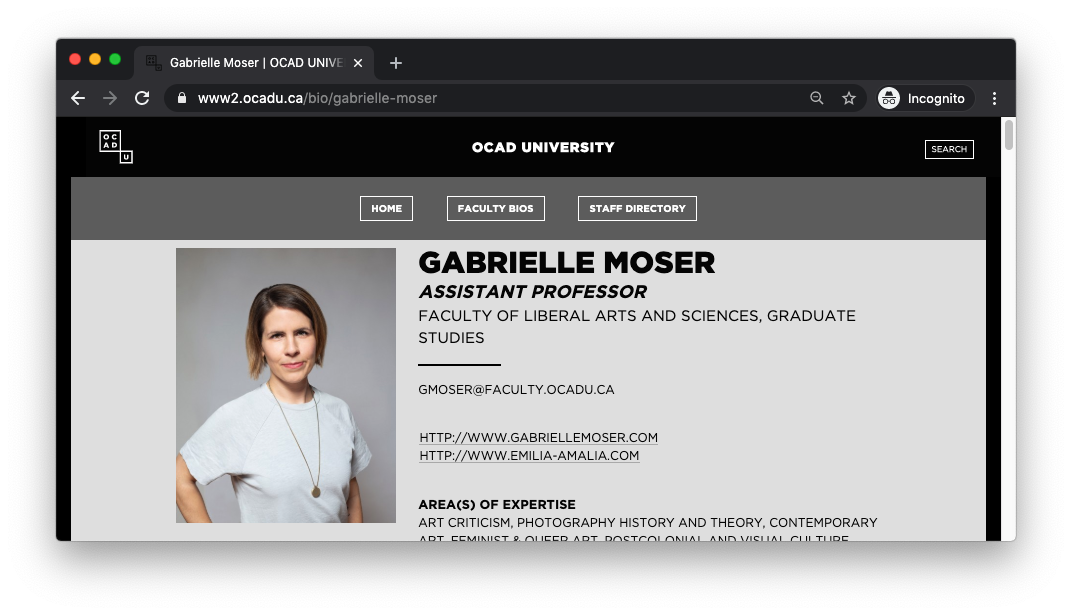
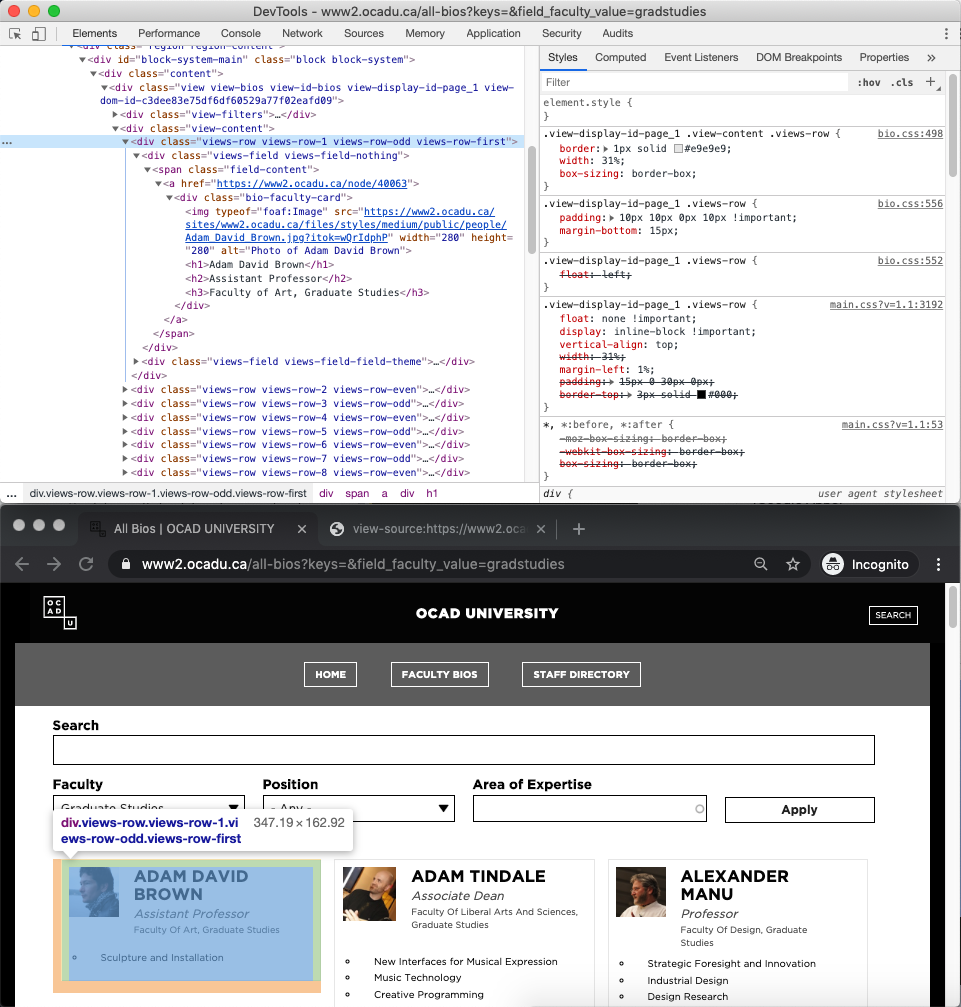
As there is no obvious pattern to how these profile URLs are generated, we are expected to use regular expression in each faculty list page to identify them. Some investigation with Inspect Element (on Chrome) suggests that each profile is neatly organized in a div element with class name views-row:
PHP Live Regex: List
We can begin our investigation by taking the entire source code (Cmd+Alt+U on Chrome for Mac) from the list page and opening it on PHP Live Regex, a web-based tool that serves as a regex playground and PHP code generator.
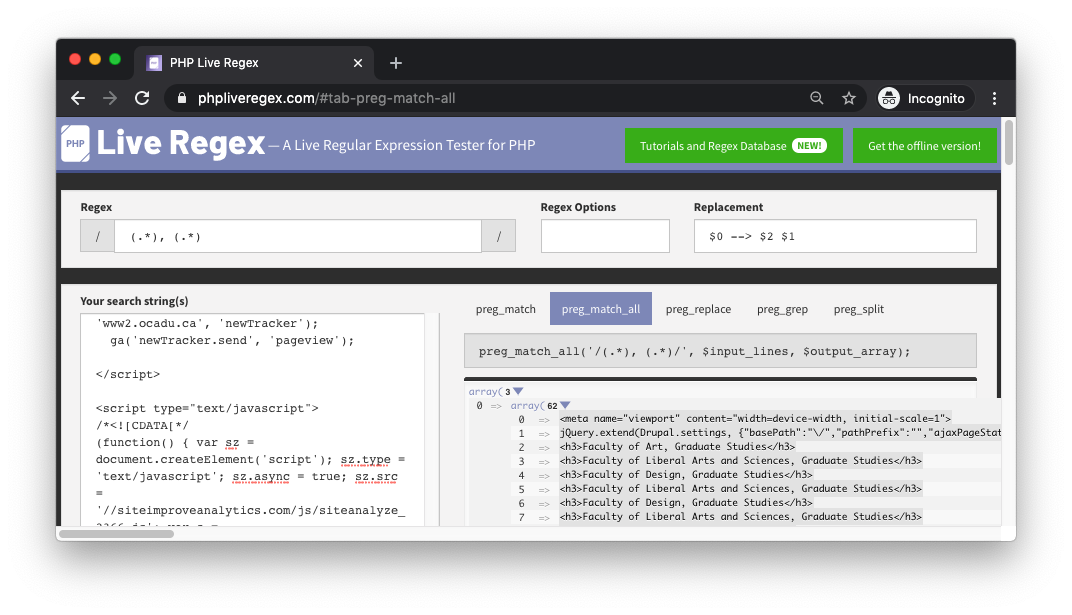
Upon setting the mode to preg_match_all, a function that combs through the entire text for patterns, we can see that a number of matches emerge already based on the preset regex (.*), (.*).
Code fragment
Below is the source code fragment that represents each card in the list:
<div class="views-row views-row-1 views-row-odd views-row-first">
<div class="views-field views-field-nothing">
<span class="field-content"><a href="https://www2.ocadu.ca/node/40063">
<div class="bio-faculty-card">
<span class="field-content"><img alt="Photo of Adam David Brown" height="280" src="https://www2.ocadu.ca/sites/www2.ocadu.ca/files/styles/medium/public/people/Adam_David_Brown.jpg?itok=wQrIdphP" typeof="foaf:Image" width="280"></span>
<h1><span class="field-content">Adam David Brown</span></h1>
<h2><span class="field-content">Assistant Professor</span></h2>
<h3><span class="field-content">Faculty of Art, Graduate Studies</span></h3>
</div></a></span>
</div>
<div class="views-field views-field-field-theme">
<div class="field-content">
<div class="item-list">
<ul>
<li class="first last">Sculpture and Installation</li>
</ul>
</div>
</div>
</div>
</div>Focus on line 3, where we can find the individual profile URL. There is a good chance that all other 47 entries will follow the same pattern, and we can craft the following regex:
<span class="field-content"><a href="(.*?)">
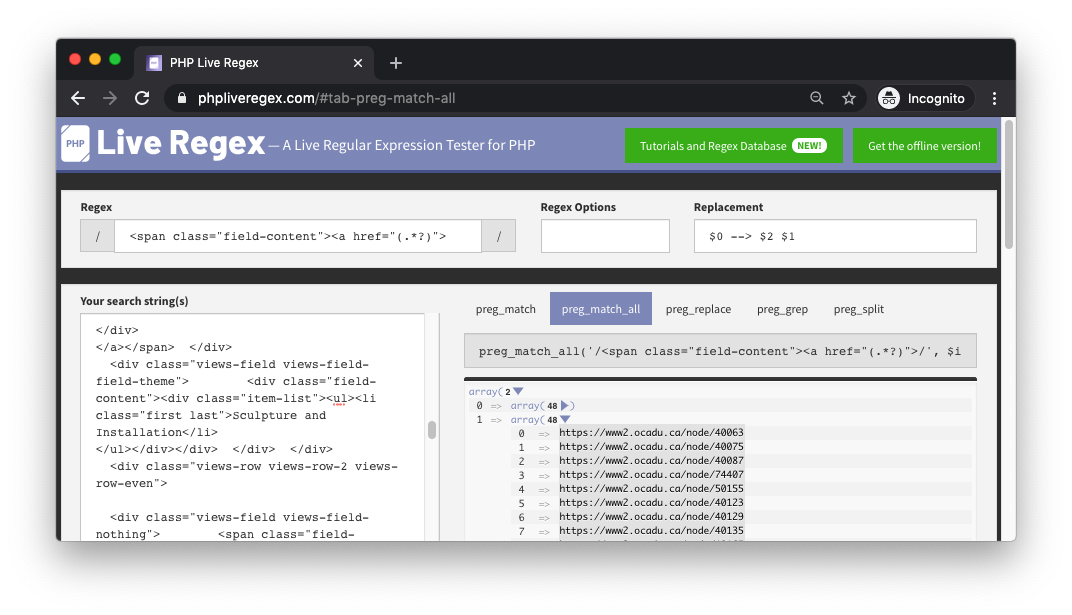
Array size 48 suggests that the above regex indeed maps to all of 48 list entries. As stipulated in the regex, this also gives us a list of URLs attached to the entries. We can keep the following PHP code snippet in mind:
preg_match_all('/<span class="field-content"><a href="(.*?)">/', $input_lines, $output_array);
PHP Live Regex: Profile
We can apply the same principle to further analyze and capture necessary information in each individual profile page.
Code fragment
Fortunately, we can see that this page is more semantically valid, where each HTML element's class name corresponds to the data point it holds:
<div class="bio-header">
<section>
<div class="bio-image"><img alt="Photo of Adam David Brown" height="600" src="https://www2.ocadu.ca/sites/www2.ocadu.ca/files/styles/medlarge__500-_/public/people/Adam_David_Brown.jpg?itok=GaILniNX" typeof="foaf:Image" width="450"></div>
<div class="bio-card">
<div class="bio-title">
Adam David Brown
</div>
<div class="bio-connection">
Assistant Professor
</div>
<div class="bio-faculty">
Faculty of Art, Graduate Studies
</div>
<div class="bio-divider"></div>
<div class="bio-phone"></div>
<div class="bio-email">
adambrown@faculty.ocadu.ca
</div>
<div class="bio-website">
<div class="item-list">
<ul>
<li class="first last">
<a href="http://www.adamdavidbrown.com" target="_blank">http://www.adamdavidbrown.com</a>
</li>
</ul>
</div>
</div>
<div class="bio-theme">
<h3>Area(s) of Expertise</h3>Sculpture and Installation
</div>
</div>
</section>
</div>As we wish to retrieve the four basic items (name, title, faculty, and email), we can try the following regex. In addition, add the regex option s in order to have the regex work across multiple lines at a time:
<div class="bio-title">(.*?)</div>.*?<div class="bio-connection">(.*?)</div>.*?<div class="bio-faculty">(.*?)</div>.*?<div class="bio-email">(.*?)</div>
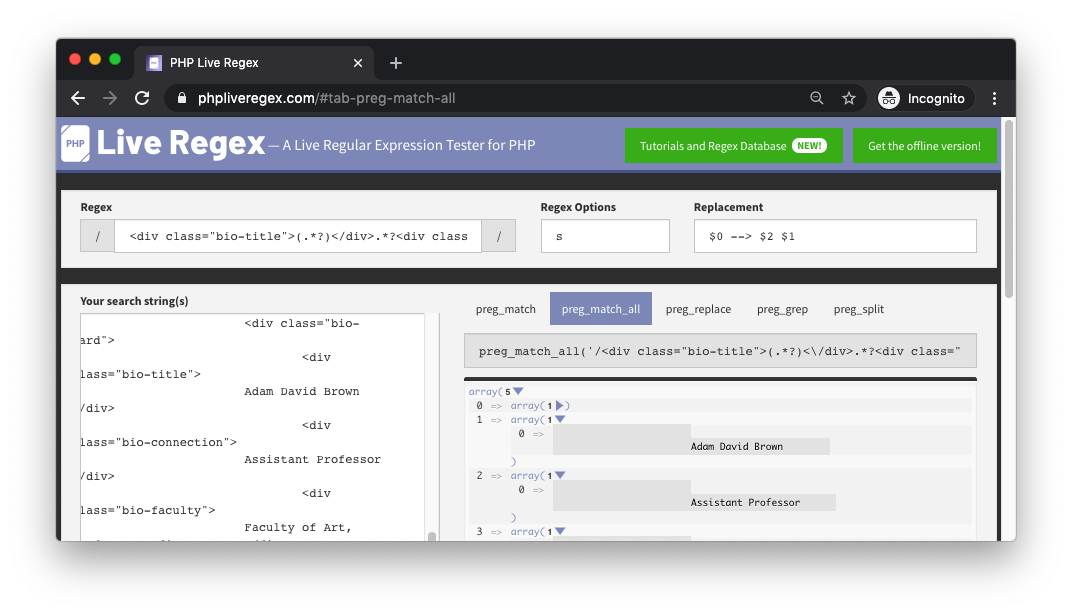
While the resultant matches do have excess whitespace due to the "quick-and-dirty" regex above, we can manage clean up at the PHP level. We will also keep the following snippet handy:
preg_match_all('/<div class="bio-title">(.*?)<\/div>.*?<div class="bio-connection">(.*?)<\/div>.*?<div class="bio-faculty">(.*?)<\/div>.*?<div class="bio-email">(.*?)<\/div>/s', $input_lines, $output_array);