Downloading and Parsing HTML Page with PHP
Setup
In the similar vein as previous projects, we can set up our index.php in the following manner:
index.php
<!doctype html>
<html>
<head>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous">
</head>
<body>
<div class="container">
<div class="row">
<div class="col-12 my-5">
<? include "data.php" ?>
<h1>OCADU Faculty List</h1>
<table class="table table-sm">
<thead>
<tr>
<th>Name</th>
<th>Title</th>
<th>Faculty</th>
<th>Email</th>
</tr>
</thead>
<tbody>
<!-- ROW -->
</tbody>
</table>
</div>
</div>
</div>
</body>
</html>The page features a separate data.php module, which will contain our regex-related code. Below is a table element and its thead section that establishes the heading columns. Upon generating the desirable array, we will place our foreach loop where <!-- ROW --> is.
Retrieving Profile URLs
Given that we have a total of three pages in this filtered list, we can create a fixed loop that counts from 0 to 2 (zero-based index) and parses each downloaded page with regex.
data.php
<?
$opts = array(
'ssl' => array(
'verify_peer' => false,
'verify_peer_name' => false
)
);
$context = stream_context_create($opts);
$profiles = array();
for ($i = 0; $i <= 2; $i++) {
$list = "https://www2.ocadu.ca/all-bios?keys=&field_faculty_value=gradstudies&page=".$i;
$input_lines = file_get_contents($list, false, $context);
preg_match_all('/<span class="field-content"><a href="(.*?)">/', $input_lines, $output_array);
$urls = $output_array[1];
foreach ($urls as $url) {
$profiles[] = $url;
}
}
echo "<pre>";
var_dump($profiles);
echo "<pre>";
?>The above code snippet achieves the following:
- Configure the script to suppress potential SSL errors when connecting to remote URLs
- Create a new variable
profilesthat will host all the individual profile URLs - Counting from 0 to 2, generate a corresponding list URL under
list - Use PHP to download the page file, and save as
input lines - Based on the previous snippet offered by PHP Live Regex, use regex to retrieve all profile URLs that match the pattern
- Create a new variable
urlsthat refers to a specific portion of the resultantoutput_arrayvariable - Iterate through the above
urlsarray and insert individual profile URLs into theprofilesvariable
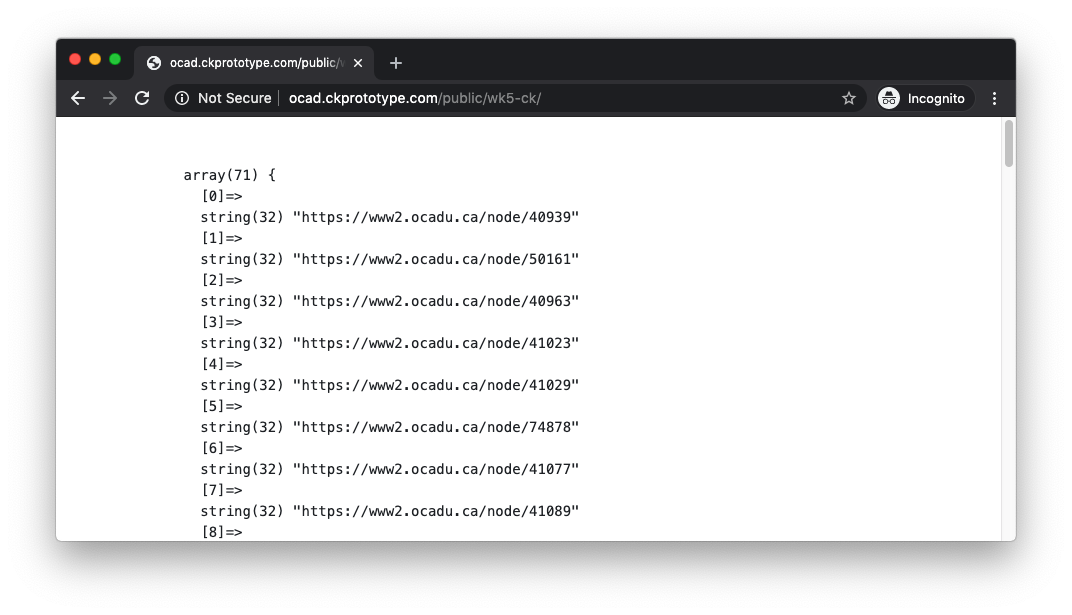
The result is a satisfactory one: we can see that the profiles array now contains a complete list of faculty member URLs, which we can once again iterate to retrieve more information about each member.
Extracting Information from Profile URLs
Continuing from above, we can now create a loop for the exhaustive profiles variable:
data.php
...
$profiles = array_slice($profiles, 0, 5);
$table = array();
foreach ($profiles as $url) {
$input_lines = file_get_contents($url, false, $context);
preg_match_all('/<div class="bio-title">(.*?)<\/div>.*?<div class="bio-connection">(.*?)<\/div>.*?<div class="bio-faculty">(.*?)<\/div>.*?<div class="bio-email">(.*?)<\/div>/s', $input_lines, $output_array);
$row = array();
$row[0] = trim($output_array[1][0]);
$row[1] = trim($output_array[2][0]);
$row[2] = trim($output_array[3][0]);
$row[3] = trim($output_array[4][0]);
$table[] = $row;
}
echo "<pre>";
var_dump($table);
echo "<pre>";
?>The above code snippet sets out to achieve the following:
- Create a new variable
tablethat will contain all the organized data - Iterate through the
profilesvariable, downloading the page and applying the code snippet from the exercise - Create a new variable
rowin the loop, which receives pertinent data from different parts ofoutput_array - Add the
rowto the previoustablevariable, building the list of faculty members
It is important to note that the above code snippet only takes the first five profile URLs in the interest of loading time: after all, the array does contain a large number of remote URLs. One can disable this array_slice function towards the end of the exercise in order to download from all the profiles.
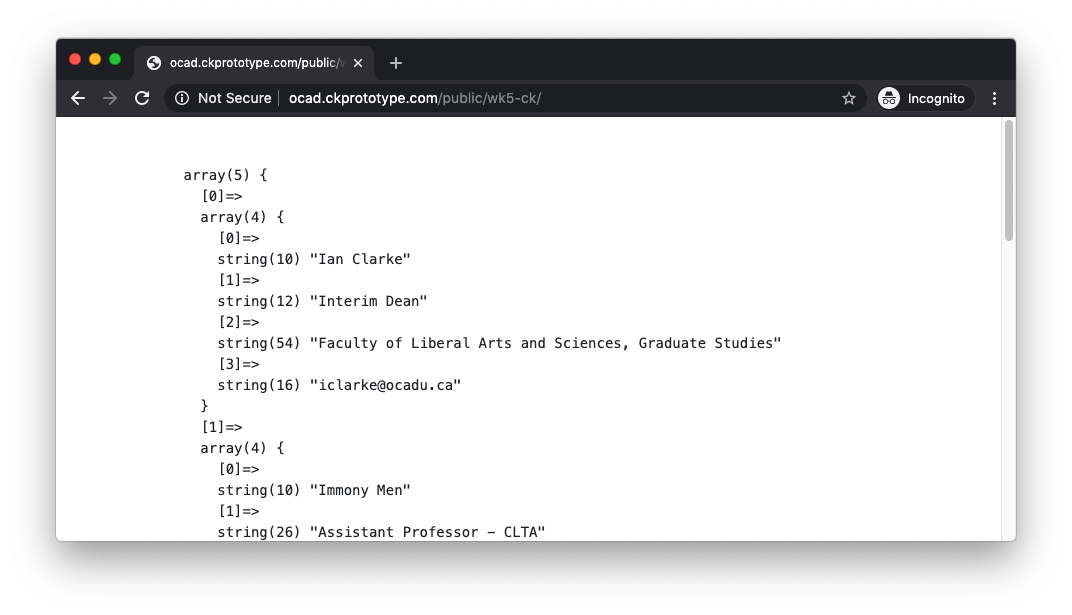
We can now move back to index.php to display this information in a user-friendly fashion, after displaying all the debug code snippets including var_dump().